
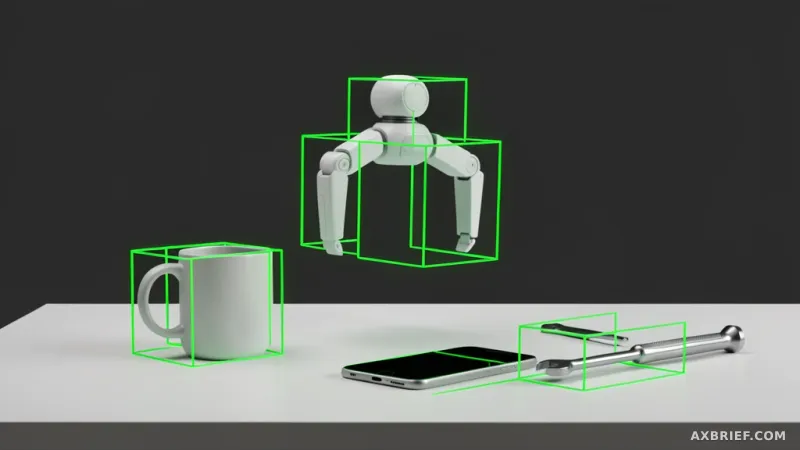
Developers building AI agents have long faced a frustrating lag between a model perceiving an object and the system executing an action. Whether it is a robotic arm attempting to grasp a specific tool in a cluttered warehouse or a software agent trying to click a confirmation button on a complex dashboard, the bottleneck is almost always the same. The system must translate a text command into precise pixel coordinates, a process known as visual grounding. Until now, this translation has felt more like a slow transcription than a real-time reflex, leaving a gap between the AI's cognitive understanding and its physical or digital execution.
Parallel Box Decoding and the Architecture of LocateAnything-3B
The primary reason for this latency in traditional visual language models is their reliance on autoregressive generation. In these systems, bounding box coordinates are generated as a sequence of tokens, one after another. This sequential approach not only slows down inference but often introduces geometric inconsistencies, where the predicted coordinates fail to align logically. NVIDIA addresses this structural flaw with LocateAnything-3B, which replaces sequential generation with a parallel box decoding mechanism. By predicting all coordinate values simultaneously in a single parallel step, the model eliminates the overhead of token-by-token generation and increases throughput by up to 2.5 times.
Under the hood, LocateAnything-3B is a hybrid powerhouse combining the Qwen2.5-3B-Instruct language model with the MoonViT-SO-400M vision encoder. The MoonViT-SO-400M encoder is specifically designed to extract high-resolution features from images, converting visual data into numerical representations that the language model can then map to specific text queries. This optimized pairing ensures that the model maintains high precision in grounding without overloading hardware resources, effectively minimizing inference latency for edge and cloud deployments.
The model's robustness stems from a massive training regimen. NVIDIA utilized 12 million images and 138 million queries to establish a foundational understanding of spatial relationships. To refine the accuracy of object localization, the team integrated 785 million bounding box data points. The training set is intentionally diverse, spanning natural landscapes, robotics, autonomous driving, GUI interactions, and complex document layouts. By exposing the model to environments with dense, overlapping objects, NVIDIA reduced detection misses and equipped the model with long-tail detection capabilities, allowing it to identify rare objects that typically vanish in smaller datasets.
Currently, the model is released under a specific NVIDIA license restricted to non-commercial academic and non-profit research. Researchers can deploy the model into their testing environments using the following command:
huggingface-cli download nvidia/LocateAnything-3BFor those requiring deeper technical implementation details, the full source code and implementation guides are available via the NVlabs/Eagle/Embodied GitHub repository. NVIDIA also provides an online demo through Hugging Face Spaces to allow for immediate verification of the model's coordinate prediction performance.
From GUI Agents to the Frontier of Physical AI
The 2.5x increase in speed is not merely a benchmark victory; it fundamentally changes the utility of AI in unpredictable environments. In the realm of Physical AI, the ability to handle open-set detection is critical. Most models struggle when they encounter an object they were not explicitly trained on. LocateAnything-3B, however, leverages its vast training data to identify unfamiliar objects and pinpoint their coordinates without requiring the developer to collect thousands of new images for fine-tuning. This is particularly transformative for precision manufacturing, where a robot may need to identify a rare spare part or a specialized industrial tool in a cluttered workspace. By lowering the false-negative rate for rare objects, the model moves AI out of the controlled laboratory and into the chaotic reality of the factory floor.
This capability extends equally to the digital world through the creation of high-performance interactive agents. For an AI to operate software on behalf of a user, it must possess a flawless understanding of GUI elements. LocateAnything-3B can instantly locate buttons, input fields, and menus within complex software interfaces. When applied to document analysis, the model combines layout grounding with Optical Character Recognition (OCR). While traditional OCR focuses on extracting the text itself, this approach identifies the exact coordinates of table borders, headers, and formatting elements. This allows the AI to preserve the visual structure of a PDF or scanned document while converting it into structured data, enabling a user to simply ask for a specific function in natural language and have the AI find and click the correct button immediately.
To make these capabilities immediately accessible, NVIDIA has integrated this high-speed grounding functionality into the Nemotron 3 Nano Omni model. This integration allows developers to deploy multimodal agents that can understand and manipulate GUIs in real-time. Furthermore, the model can be utilized to automate the data labeling process, drastically reducing the time and cost associated with manual annotation for other vision models. Local testing and deployment can be initiated with the same command:
huggingface-cli download nvidia/LocateAnything-3BDetailed optimization methods and implementation code remain hosted at the NVlabs/Eagle/Embodied repository, ensuring that the research community can iterate on the architecture. The shift toward high-speed, precision grounding provides the necessary infrastructure for a new generation of agents that do not just describe the world, but actively navigate it.
The reduction in inference latency transforms the logic of AI control from a series of discrete, slow calls into a continuous, real-time feedback loop. As the efficiency of converting visual coordinates to text increases, the interface between AI and the physical world becomes seamless, setting a new standard for how autonomous systems interact with their surroundings.



