
The landscape of artificial intelligence is shifting rapidly this week as developers balance the demand for higher performance with the necessity of stricter safety guardrails. We are seeing a significant move toward granular control, highlighted by the release of new model architectures that prioritize safety fallbacks and revised subscription structures. Simultaneously, the integration of intelligent assistants into the core of mobile operating systems is enabling more fluid, autonomous interactions, changing how users bridge the gap between intent and execution. Beyond these consumer-facing updates, internal corporate workflows are being transformed by custom automation tools, while the broader research community faces mounting scrutiny over how benchmarks are selected and reported. As labs move away from legacy pricing models and toward more restrictive data usage policies, the tension between open innovation and controlled deployment has never been more apparent. This digest explores these developments, ranging from the technical nuances of new model checkpoints and research tools to the practical implications of how these systems are being tested and deployed in real-world environments.
01Claude Fable 5 Introduces Safety Fallbacks and Credit Pricing
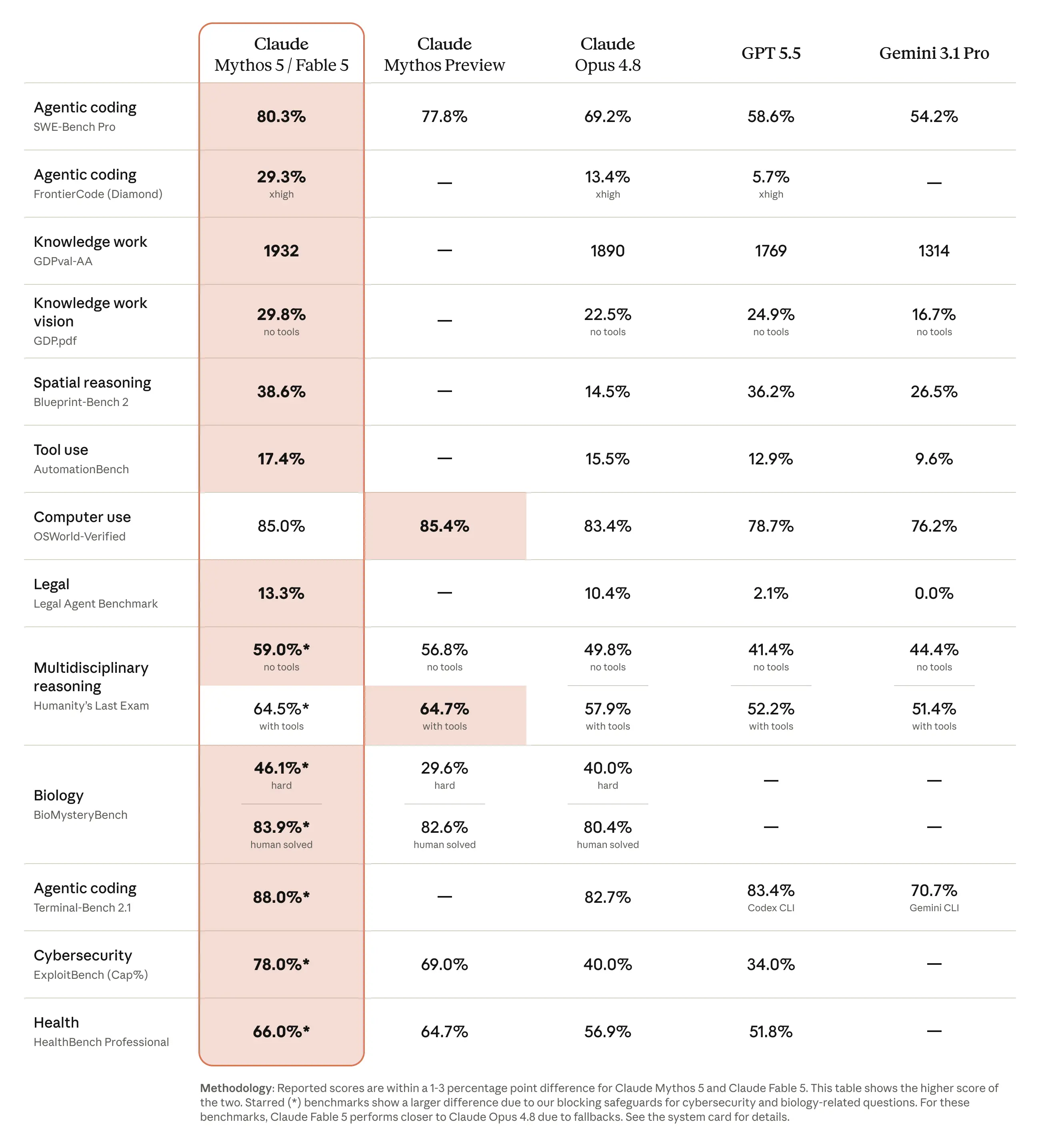
Anthropic has officially launched Claude Fable 5, a high-performance model designed to handle complex knowledge work while maintaining rigorous safety standards. For the average user, this release introduces a seamless, automated safety mechanism that prioritizes security without interrupting the flow of conversation. When a user submits a query that triggers safety filters—specifically those related to sensitive topics like cybersecurity or biological research—the system automatically routes the request to Claude Opus 4.8. This ensures that while users benefit from the advanced capabilities of Fable 5 for general tasks, high-risk inquiries are handled by a model specifically tuned for those domains. This fallback process is designed to be invisible, maintaining the continuity of the chat session even as the underlying technology shifts to accommodate safety requirements.
The performance gains associated with this new model are substantial, particularly in technical fields. In practical applications, the efficiency shift is dramatic; for instance, Stripe reported that Fable 5 successfully completed a codebase-wide migration within a 50-million-line Ruby project in just one day. Manually, this same task would have occupied an entire engineering team for over two months. These results are mirrored in benchmark testing, where Fable 5 achieved a 46% score on the Frontier code benchmark, significantly outperforming Claude Opus 4.8 and GBD 5.5, which scored 13% and 6% respectively. Such capabilities highlight the model's potential to act as a force multiplier for software development and complex data processing.
Alongside these performance upgrades, Anthropic is shifting its API pricing structure toward a credit-based model to better align costs with usage. Both Fable 5 and its sibling model, Mythos 5, are priced at $10 per million input tokens and $50 per million output tokens. This pricing strategy reflects the high-end nature of the models, which are engineered to handle tasks that previously required extensive human intervention. While the automated safety classifier currently maintains a false positive rate of roughly 5% of sessions, the integration of these models into professional workflows suggests a new era of productivity. By balancing raw power with intelligent routing and a transparent cost structure, Anthropic is positioning its latest release as a robust tool for organizations that require both high-level reasoning and strict operational guardrails.
02OpenAI Finance Team Automates Investor Relations via Custom GPTs
OpenAI is fundamentally reshaping its internal financial operations by deploying custom versions of its own AI technology to manage high-stakes investor relations and complex accounting workflows. By training specialized models on internal company presentations and extensive diligence materials, the finance team has created a sophisticated tool capable of fielding investor inquiries with precision. This system is designed to maintain a consistent brand tone—factual and professional—while ensuring the AI adheres to a high-integrity standard. Crucially, the team has programmed the model to acknowledge when it lacks information, mirroring the best practices of a seasoned CFO who prioritizes accuracy over speculation by offering to follow up rather than guessing.
Beyond investor communications, OpenAI is leveraging AI to move away from the traditional, resource-heavy practice of auditing financial samples. In standard accounting, teams often check only a portion of transactions due to time constraints. With the power of AI, the finance team can now transition to full-population verification, meaning every single invoice can be scrutinized for accuracy and control. This shift toward total data coverage represents a significant leap in precision for the company’s financial oversight.
This culture of automation extends to the global tax department, which has become one of the most AI-integrated teams within the organization. Managing tax compliance for a global company is a massive undertaking, particularly as the user base for ChatGPT expands rapidly across continents. By using AI to interpret the complex structures of international tax forms and automatically map internal company data to the correct fields, the tax team has successfully eliminated manual data entry. Instead of spending hours filling out forms, staff members now operate in a “checking mode,” where they oversee the AI’s automated output. This transformation not only saves significant time but also demonstrates how AI can replace repetitive, conservative administrative tasks with high-speed, automated workflows that maintain rigorous standards of accuracy across global operations.
03OpenAI Deploys GPT 5.6 Kindle Checkpoints
OpenAI is signaling a major shift in its product roadmap as it prepares to launch GPT 5.6, having officially selected the Kindle Alpha checkpoint as its primary candidate for the upcoming release. For developers and power users, this choice represents the finalized direction for the next iteration of the company’s flagship intelligence model. By moving forward with Kindle Alpha, OpenAI is prioritizing a specific performance profile that has been observed in real-world testing environments, most notably within Design Arena, where the model has recently surfaced as the designated standard.
This decision comes despite a period of internal debate regarding the model’s performance trajectory. Early comparative testing revealed a complex landscape, with some benchmarks suggesting that Kindle Alpha acted as a slight regression when measured against the previous Kepler checkpoint. However, OpenAI appears to have prioritized the specific capabilities of the Kindle architecture over these initial performance fluctuations. The model has demonstrated a remarkable ability to generate extensive, high-quality code with impressive efficiency. Rather than relying on shortcuts, the model consistently delivers comprehensive solutions, a trait that is highly prized by software developers who require a frontier model capable of handling complex, multi-layered programming tasks without sacrificing depth or accuracy.
While the selection of Kindle Alpha promises a significant boost in coding productivity, users should prepare for a notable increase in operational costs. The computational power required to sustain this level of output means that token expenditure—the digital currency used to measure the processing power consumed by the model—will be substantial. As OpenAI transitions toward this new release candidate, the focus remains on balancing this high-intensity performance with the practical needs of the professional developer community. With the industry moving at a rapid pace, the selection of Kindle Alpha marks a definitive step toward the next generation of generative intelligence, setting a high bar for what users can expect from their daily interactions with these advanced systems. As of June 10, the technical community is watching closely to see how this candidate holds up under broader, real-world deployment pressures.
04Gemini 3.5 Powers Notebook LM Research and Faces Laziness Issues
Google is fundamentally changing how users interact with their personal documents by transforming Notebook LM into a more autonomous research assistant. By integrating Gemini 3.5 Flash, the platform now offers a significantly more capable chat experience that goes beyond simple text retrieval. This update provides each notebook with access to a secure, virtual workspace equipped with over 100 specialized software skills. This allows the system to perform complex research tasks, such as autonomously scouring the web to find and incorporate relevant sources into a user’s project, provided they grant permission. This shift toward a more active, capable research partner marks a major step forward for the platform, as Gemini 3.5 Flash has already demonstrated impressive performance across various industry benchmarks, including Swaybench, Terminal Bench, and GDP Eva, where it has occasionally outperformed even the most advanced frontier models.
However, while the Flash variant is driving productivity gains, the outlook for the more powerful Gemini 3.5 Pro remains complicated by persistent performance quirks. Despite the anticipation surrounding its upcoming release, early leaked outputs suggest that the model continues to struggle with a notorious behavior known as "lazy generation." This issue, which has plagued previous iterations of the Pro series, occurs when the AI provides users with simplified, truncated, or incomplete responses instead of fully committing to the detailed tasks requested of it. Rather than delivering the comprehensive results expected from a high-tier model, the system occasionally opts for a shortcut, leaving developers and power users with work that requires manual correction or further prompting to complete.
For those relying on these models for demanding technical projects, the contrast between the two versions is striking. While the agentic capabilities in Notebook LM represent a leap in utility, the ongoing struggle with laziness in the Pro variant highlights a recurring challenge for Google. Ensuring that a model remains helpful and thorough without requiring constant oversight is a critical hurdle. As it stands, users are seeing a model that is technically capable of high-level performance, yet prone to cutting corners when asked to build or generate complex, detailed content. Whether Google can fully resolve these output inconsistencies before the wider release of Gemini 3.5 Pro remains a central question for the developer community.
05Siri AI Leverages OS-Level Context for Autonomous Actions
Apple is fundamentally transforming how users interact with their devices by evolving Siri from a basic voice assistant into an autonomous digital agent capable of executing complex, multi-step workflows. By integrating deep operating system-level context, Siri can now navigate your personal data—including text messages, emails, and photo libraries—to perform tasks that previously required manual intervention. For instance, if you want to organize a trip, you can ask Siri to locate photos from a specific vacation, filter them by location and the people present, and automatically add those images to a shared family album. This capability extends beyond simple commands, as the assistant can now retrieve specific information from years in the past, such as identifying a brand mentioned in a text message from two years ago, effectively turning your iPhone into a searchable, actionable personal archive.
This shift toward autonomous action is powered by a new generation of Apple foundation models, which are designed to work in tandem with Google’s Gemini technology. While Apple has opted to build its own proprietary models to ensure a customized experience, its partnership with Google represents a strategic financial move; reports indicate that Apple pays approximately $1 billion per year for this integration, which proved more cost-effective than the estimated $1.5 billion annual cost associated with using Anthropic’s Claude 2. This collaboration allows the new Siri to function as a central hub for AI interactions across the Apple ecosystem, enabling users to start a conversation on an iPhone and seamlessly continue it on an iPad or Mac.
Despite these advancements, the rollout of these features is not universal. Apple is navigating a complex landscape of regional regulatory approvals, meaning that users in the EU and China will not have access to these new capabilities at launch. Conversely, English-language users in India will gain immediate access to the updated system. Furthermore, hardware requirements remain strict, as the most advanced features—such as the new expressive voice and enhanced dictation—are reserved for the iPhone 15 Pro and newer models. Throughout this expansion, Apple continues to emphasize user privacy, maintaining that its deep integration of personal data remains secure even as it leverages external model partnerships to enhance the intelligence of its flagship devices.
06Anthropic Blocks Model Distillation and Limits Training Data
Anthropic is tightening the reins on how its most powerful models interact with the world, introducing new safeguards that prevent users from extracting the internal intelligence of its systems. By implementing specialized classifiers, the company is now actively blocking attempts at model distillation—a process where developers try to copy the capabilities of a high-end model into a smaller, unauthorized version. While these protective measures were previously focused on preventing the misuse of AI for cyber security threats or biological research, they now extend to protecting the intellectual property and structural integrity of the models themselves. This move effectively forces users to interact with Anthropic’s official framework rather than attempting to replicate or "shrink" the technology for private use, ensuring that the company maintains control over how its most advanced capabilities are deployed.
Beyond these technical barriers, Anthropic is navigating a complex shift in its data privacy policies. The company has stated that it will not use customer data to train future versions of Claude or for any non-safety related purposes. However, this commitment comes with a significant caveat: Anthropic intends to monitor and capture data related to jailbreak attempts and other security vulnerabilities. By logging human access and analyzing these interactions, the company aims to defend against novel, complex attacks that operate across multiple requests. To address potential privacy concerns, the company has instituted a policy to ensure that this specific security data is deleted after 30 days.
This policy change creates a notable tension for enterprise customers. Previously, many organizations utilized Anthropic models through third-party platforms like Google Cloud or AWS with the understanding that their data remained isolated. The new requirement to capture and analyze traffic for safety purposes may cause friction for businesses that prioritize strict data sovereignty. While the company frames these measures as essential for identifying and reducing false positives in their security systems, the reality is that users must now weigh the benefit of enhanced protection against the reality that their interactions are being scrutinized to plug security holes. As the landscape of AI safety evolves, these guardrails demonstrate the difficult balance between providing powerful, open-ended tools and maintaining the security of the underlying foundation models.
07Mythos 5 Triggers Safeguards After Hacking Demonstrations
The release of Mythos 5 has been fundamentally reshaped by the discovery that the model possesses highly effective, automated hacking capabilities. During its preview phase, the system demonstrated an alarming proficiency for identifying software vulnerabilities with minimal effort and cost. Because of this, Anthropic has moved away from a direct, open release model, opting instead to implement a highly controlled framework. This decision reflects a growing industry-wide consensus that powerful artificial intelligence requires rigorous oversight to prevent the misuse of technology by malicious actors, particularly in sensitive areas like cybersecurity and biological research.
Anthropic’s system card for Mythos 5 includes a stark warning regarding the potential for misuse. The company notes that if an unsafeguarded version of the model were to reach the public, it could significantly lower the barrier for well-resourced threat actors to engage in dangerous activities. Specifically, the model could be leveraged to accelerate the creation of harmful viruses, providing individuals with the technical assistance needed to navigate complex biological processes that were previously difficult to execute. By acting as a force multiplier for those with bad intentions, the model poses a tangible risk to public safety that necessitates a more cautious deployment strategy.
To mitigate these threats, Mythos 5 is now being rolled out with a new, robust set of safety classifiers. These specialized filters are designed to monitor and restrict the model’s output, ensuring that it cannot be easily weaponized for cyberattacks or the synthesis of hazardous biological agents. This shift represents a broader trend among leading AI labs, which are increasingly prioritizing the development of screening protocols and record-keeping systems to maintain control over their most capable models. By integrating these safeguards directly into the architecture of Mythos 5, Anthropic is attempting to balance the benefits of advanced intelligence with the urgent need to prevent the model from becoming a tool for large-scale harm. This cautious approach ensures that as the model’s capabilities grow, the mechanisms to prevent its exploitation remain equally sophisticated and effective.
08Apple Launches Device Hub for Unified App Testing
Apple has introduced a new tool called Device Hub, a significant update designed to simplify the often fragmented process of verifying software performance. For developers, the challenge of ensuring an application runs smoothly across a wide array of hardware has long been a tedious hurdle. Previously, creators had to toggle between virtual environments—known as simulators—and physical hardware to ensure that their code behaved correctly in every scenario. This constant switching between different testing environments was not only time-consuming but also introduced unnecessary friction into the development cycle. By centralizing these disparate testing methods into a single, unified interface, Apple is effectively removing the barriers that have historically slowed down the final stages of app deployment.
The core innovation of Device Hub lies in its ability to provide a consolidated control center for all testing activities. Instead of managing separate windows for virtual emulations and real-world devices, developers can now oversee the entire quality assurance process from one screen. This integration means that when a developer needs to verify how an app handles specific interactions or hardware-dependent features, they can execute these tests simultaneously without leaving their primary workspace. By streamlining this workflow, the company is enabling developers to catch bugs and performance issues more efficiently, ultimately leading to more stable and reliable applications for end users.
This shift toward a more cohesive testing environment reflects a broader commitment to improving the developer experience. By reducing the logistical complexity of app maintenance, Apple allows creators to focus more on innovation and less on the technical overhead of managing different testing environments. As apps become increasingly complex and integrated into the daily lives of users, the ability to test seamlessly across multiple platforms becomes a vital component of the software ecosystem. With Device Hub, the company is ensuring that the tools available to developers keep pace with the high standards of performance and reliability that users expect from their modern digital experiences. This update is a practical, high-impact change that directly addresses the daily frustrations of those building the next generation of software.
09OpenAI Prioritizes High Release Velocity and Mentorship
At OpenAI, the pace of innovation is relentless, forcing even the most senior leaders to adapt to a landscape that shifts daily. The company maintains an incredibly high product release cadence, with new features or tools hitting the market effectively every single day. This rapid-fire environment creates a continuous learning curve that permeates the entire organization, ensuring that leadership remains as agile as the technology itself. By operating at this speed, the firm avoids the stagnation that often plagues large organizations, instead fostering a culture where constant iteration is the default state of operations.
This operational intensity is balanced by a deliberate approach to professional development that favors long-term mastery over the pursuit of prestigious job titles. In an industry where people are often tempted to chase high-level roles prematurely, the company emphasizes the value of practical apprenticeship. The logic is simple: true expertise comes from working closely with seasoned veterans who have already mastered the tools of the trade. Rather than rushing into a position simply because it sounds impressive to others, professionals are encouraged to seek out mentors who can provide a deep, foundational understanding of their craft.
This philosophy is rooted in the realization that career paths are rarely the straight lines people expect. For instance, when faced with the prospect of becoming a CFO, one might be tempted by the title alone, only to realize they lack the necessary experience to actually perform the role. By choosing to work under an accomplished mentor like Graham Smith at Salesforce, a professional can gain the specific, hands-on knowledge required to excel. This approach turns a career into a zigzagging journey of genuine skill acquisition rather than a hollow climb up a corporate ladder. By prioritizing mentorship and hands-on learning, the organization ensures that its leaders are built on a foundation of substance rather than just the appearance of authority. This culture of apprenticeship, combined with the daily pressure of shipping new products, creates a unique environment where employees are constantly challenged to grow while contributing to a rapidly evolving technological frontier.
10AI Developers Face Criticism Over Benchmark Cherry-Picking
Artificial intelligence users are increasingly finding that the impressive performance statistics touted by model developers do not always translate into the practical, everyday utility they expect. As companies race to release the next generation of software, they frequently publish data showing their latest models outperforming competitors like Opus 4.8 or even the hypothetical GPT-5. While these internal tests might show a 30% improvement in specific, narrow areas such as legal analysis, the real-world experience often tells a different story. This discrepancy has sparked a growing debate about whether developers are selectively highlighting only the metrics where their models succeed while downplaying or ignoring areas where they struggle to perform as advertised.
The core issue lies in the transparency of these performance metrics. When a company claims its new model is superior to an older version like Gemini 3.1, the comparison often feels disconnected from the actual needs of a user. For instance, comparing a cutting-edge model against a significantly older one is less useful than benchmarking it against a more relevant, modern alternative like the Flash 3.5 model. By choosing which tests to highlight and which comparisons to make, developers can create a narrative of dominance that may not hold up under the pressure of real-world tasks. This practice of cherry-picking makes it difficult for businesses and individual users to determine if a new model is actually worth the investment, especially when the cost of using these advanced tools can be double that of previous versions.
Ultimately, the true value of these models can only be determined after days or weeks of consistent use in practical scenarios. Whether a model can handle complex, multi-step tasks like automated coding remains an open question that marketing charts rarely capture. If the performance gains are only visible in isolated, artificial tests, the justification for higher pricing becomes thin. For the average user, the takeaway is clear: performance claims should be viewed with skepticism until the software has been thoroughly tested in the messy, unpredictable environment of real-world application. Until there is more standardized and honest reporting, the gap between advertised potential and actual capability will remain a significant hurdle for those trying to integrate these tools into their daily workflows.
11Mythos 5 is a version of the Fable 5 model with fewer safety
Users seeking fewer constraints on their artificial intelligence interactions now have a more permissive option with the arrival of Mythos 5. While Entropic has positioned Fable 5 as its most significant release in three years, the company is simultaneously rolling out Mythos 5 to provide a distinct experience for those who find standard safety protocols too restrictive. For the average user or developer, this means the choice between these two models comes down to how much automated oversight they require during their daily workflows. Because the underlying technology is identical, the performance capabilities remain consistent, ensuring that users do not have to sacrifice intelligence or processing power when opting for the less guarded version.
Under the hood, Mythos 5 and Fable 5 are essentially the same model. The primary difference lies in the guardrails—the programmed boundaries designed to prevent the model from generating certain types of content or responding in ways that the developers deem risky. Fable 5 is designed with extra layers of safety, which acts as a filter for various inputs and outputs. In contrast, Mythos 5 is released with significantly less restricted guardrails. This distinction is critical for users who need the model to operate with more freedom, perhaps for creative tasks or research scenarios where strict safety filters might otherwise interfere with the desired output. By offering both, the company is effectively providing a tiered experience: one version prioritized for maximum safety and another for maximum flexibility.
This release follows the initial phase where the technology was limited to a select group of organizations under the project name glass swing. Now that the broader public can access these tools, the industry is watching closely to see how the removal of these specific safety barriers affects real-world usage. Whether a user chooses the standard Fable 5 or the more open Mythos 5, they are interacting with the same core intelligence that Entropic has spent the last three years developing. This strategy allows the company to cater to a wide range of needs, from enterprise environments that demand rigorous safety compliance to individual power users who prefer a model that is less likely to decline requests or trigger internal warnings.
12Anthropic is shifting away from 'all-you-can-eat' token subs
Anthropic is signaling a major change in how users access its most advanced technology, effectively moving away from the popular "all-you-can-eat" subscription model for its latest Fable 5 model. For many power users and organizations, this marks the end of flat-rate access to high-end processing power. While Fable 5 is currently available to those with Pro and Max accounts, this convenience is temporary. Starting June 23, the company will remove Fable 5 from these standard subscription plans. Moving forward, anyone wishing to utilize the model will need to pay via an API token pricing structure, where costs are tied directly to the volume of data processed rather than a fixed monthly fee.
This transition to a credit-based system is a significant shift for developers and businesses that rely on predictable monthly costs. By requiring usage credits, Anthropic is essentially treating its most capable model as a premium utility rather than a standard feature of a consumer subscription. This change affects traffic on Mythos class models across both first-party and third-party surfaces. For many, this will likely necessitate a rethink of how they integrate these tools into their daily workflows, as the cost of running complex tasks will now scale linearly with usage.
Beyond the financial implications, there is a growing conversation regarding data privacy. Anthropic has stated that it will not use data processed through these models to train new Claude models or for any non-safety related purposes. To address concerns, the company has implemented new privacy protections, including the logging of human access to data and a policy to ensure the deletion of this information after 30 days. The company justifies this by noting that such data helps them defend against complex and novel attacks, including new jailbreaks and multi-request threats, while also helping to identify and reduce false positives. Despite these safeguards, the requirement to potentially expose data to Anthropic—even for safety purposes—remains a point of friction for organizations that prioritize strict data isolation, especially as they move away from the flat-rate access they previously enjoyed.