
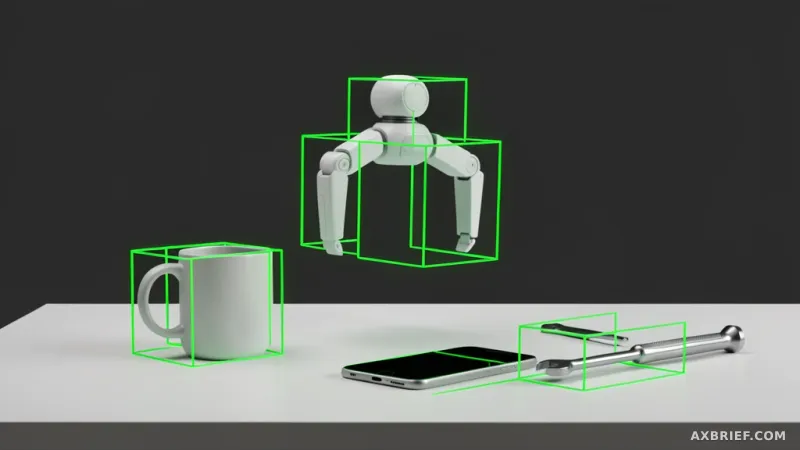
엔비디아(NVIDIA)는 AI가 세상을 보는 방식을 정의하는 기업이다. 최근 AI 에이전트가 화면의 버튼을 클릭하거나 로봇이 물건을 집어 올리려면, 텍스트 명령을 정확한 픽셀 좌표로 변환하는 '시각 언어 접지(Visual Grounding, 텍스트와 이미지의 공간적 위치를 연결하는 기술)'가 필수적이다.
하지만 기존 모델들은 좌표를 하나씩 생성하는 방식 탓에 실시간 응답 속도가 느려 실제 서비스 적용에 한계가 있었다. 엔비디아가 이번에 공개한 LocateAnything 모델은 이 병목 지점을 정면으로 돌파한다. 좌표 생성 방식을 완전히 바꾸어 추론 속도를 2.5배 높였으며, 이를 통해 가상 인터페이스 조작부터 물리적 환경 인지까지 실시간으로 처리하는 기반을 마련했다.
병렬 박스 디코딩으로 추론 속도 2.5배 높인 LocateAnything-3B
개발자가 화면에서 바운딩 박스 좌표가 하나씩 찍히는 것을 기다리는 시간은 늘 병목이었다. 기존 시각 언어 모델은 자기회귀 방식을 사용하여 좌표 토큰을 순차적으로 생성했다. 토큰을 하나씩 생성하는 과정에서 추론 속도가 느려지고 좌표 간의 기하학적 일관성이 깨지는 문제가 잦았다. 엔비디아는 좌표값을 한 번에 예측하는 병렬 박스 디코딩 방식을 도입해 이 구조를 완전히 바꿨다. 단 한 번의 병렬 단계로 전체 좌표를 동시에 출력하며 처리량을 최대 2.5배 높였다. 순차적 생성의 오버헤드를 제거해 실시간 응용이 가능한 수준으로 속도를 끌어올린 결과다.
모델 내부 구조는 Qwen2.5-3B-Instruct 언어 모델과 MoonViT-SO-400M 시각 인코더를 결합해 구축했다. 시각 인코더가 이미지의 특징을 추출해 수치 데이터로 변환하면 언어 모델이 이를 바탕으로 텍스트 쿼리와의 공간적 연결 고리를 찾는다. MoonViT-SO-400M은 고해상도 이미지에서도 세밀한 특징을 포착해 언어 모델에 전달한다. 두 모델의 최적화된 결합은 연산 부하를 줄이면서도 정밀한 접지 성능을 유지한다. 이는 하드웨어 자원을 효율적으로 사용하면서도 추론 지연 시간을 최소화하려는 설계 의도를 반영한다.
학습 단계에서는 1,200만 장의 이미지와 1억 3,800만 개의 쿼리를 사용해 모델의 기초 체력을 다졌다. 여기에 7억 8,500만 개의 바운딩 박스 데이터를 추가해 객체 위치 예측의 정확도를 높였다. 학습 데이터는 자연 경관부터 로보틱스, 자율 주행, GUI 상호작용, 문서 이해까지 산업 전반의 도메인을 아우른다. 특히 밀집된 다중 객체가 존재하는 복잡한 환경의 데이터를 대량 학습해 탐지 누락을 줄였다. 방대한 양의 좌표 데이터를 통해 희귀 객체까지 포착하는 롱테일 탐지 능력을 확보했다.
라이선스는 비상업적 용도의 학술 및 비영리 연구 목적으로만 허용되는 엔비디아 전용 라이선스를 따른다. 연구자와 개발자는 다음 명령어를 통해 모델을 내려받아 즉시 테스트 환경을 구축할 수 있다.
huggingface-cli download nvidia/LocateAnything-3B모델의 상세 코드와 구체적인 구현 방법은 엔비디아의 깃허브 저장소인 NVlabs/Eagle/Embodied에서 공개한다. 허깅페이스 스페이스를 통한 온라인 데모 체험도 지원해 접근성을 높였다. 학술적 검증을 우선시한 배포 방식을 통해 연구 생태계의 빠른 피드백을 수렴하고 모델의 완성도를 높인다.
GUI 에이전트부터 물리적 AI까지, 실무 적용 시나리오
공장 바닥에 무작위로 흩어진 수십 개의 부품이나 일반 가정집의 복잡한 집기류 사이에서 특정 물건을 찾아내는 작업은 그동안 AI 모델에게 매우 까다로운 과제였다. LocateAnything-3B는 밀집 다중 객체 탐지 능력을 통해 이러한 복잡한 환경에서 작동하는 물리적 AI(Physical AI, 실제 물리 세계와 상호작용하는 AI) 구현을 직접적으로 지원한다. 특히 학습 데이터에 포함되지 않은 생소한 객체를 찾아내는 오픈셋(Open-set) 탐지와 출현 빈도가 낮은 희귀 객체를 포착하는 롱테일 탐지 기능이 핵심이다. 개발자는 이제 수만 장의 전용 데이터를 수집해 모델을 재학습시키지 않고도 로봇이 낯선 환경의 물체를 식별하고 정확한 좌표를 찍게 만든다. 특히 희귀 객체 탐지 능력은 특수 산업 장비나 희귀 부품을 다루는 정밀 제조 공정에서 오탐지율을 낮추는 실질적인 도구가 된다. 이는 AI의 활동 영역을 통제된 실험실 수준에서 예측 불가능한 실제 산업 현장과 일상 공간으로 확장하는 결과로 이어진다.
사용자가 텍스트로 명령을 내리면 AI가 화면 속 특정 버튼의 정확한 좌표를 계산해 클릭하는 과정은 인터랙티브 에이전트(Interactive Agent, 사용자를 대신해 소프트웨어를 조작하는 AI) 시스템의 핵심 동력이다. 이 모델은 GUI 요소 접지 능력을 통해 복잡한 소프트웨어 인터페이스 내의 버튼이나 입력창 위치를 즉각적으로 찾아낸다. 문서 분석 도구를 제작할 때도 레이아웃 접지와 광학 문자 인식(OCR, 이미지 속 텍스트를 디지털 데이터로 변환하는 기술) 위치 찾기 기능을 결합한다. 기존 OCR이 텍스트 내용 추출에 집중했다면 이 방식은 표의 경계선이나 서식의 위치를 좌표 단위로 정밀하게 짚어내어 데이터 추출의 정확도를 높인다. 이는 사용자가 소프트웨어의 메뉴 구조를 외우지 않아도 자연어로 기능을 요청하면 AI가 즉시 실행 버튼을 찾아 누르는 사용자 경험을 가능하게 한다. 개발자는 이를 통해 복잡한 PDF나 스캔 문서의 시각적 구조를 그대로 보존하며 데이터를 정형화하는 정교한 분석 파이프라인을 구축한다.
엔비디아는 이러한 고속 접지 기능을 Nemotron 3 Nano Omni 모델에 통합하여 GUI 이해와 멀티모달 에이전트 기능을 즉시 서비스에 적용할 수 있도록 했다. 실무자는 자동화된 데이터셋 레이블링 공정에 이 모델을 투입해 수작업으로 진행하던 주석 달기 작업의 비용과 시간을 획기적으로 낮춘다. 모델의 배포와 로컬 테스트는 다음 명령어로 즉시 수행한다.
huggingface-cli download nvidia/LocateAnything-3B상세한 구현 코드와 최적화 방법은 NVlabs/Eagle/Embodied 깃허브 저장소에서 제공하며, 허깅페이스 스페이스(Hugging Face Spaces) 온라인 데모를 통해 실제 좌표 예측 성능을 검증한다. 고속 정밀 접지 능력은 가상 세계의 인터페이스 제어부터 실제 로봇의 시각 인지까지 아우르는 범용 시각 지각의 실무적 기반이 된다.
텍스트 좌표 추출 속도가 2.5배 빨라진 결과는 AI 에이전트의 실시간 반응성을 결정하는 핵심 지표가 된다. 추론 지연 시간이 획기적으로 줄어들면 로봇 제어나 UI 자동화 시스템의 코드 구조는 단순 호출 방식에서 실시간 피드백 루프로 전환된다. 결국 시각적 좌표를 텍스트로 치환하는 효율성이 AI가 물리적 세계와 상호작용하는 인터페이스의 표준을 결정한다.



