The current race in artificial intelligence has shifted from a quest for sheer scale to a battle for extreme efficiency. For developers and users alike, the dream is on-device AI: a system that processes complex data locally without relying on a cloud connection. This shift is driven by the urgent need for lower latency and heightened data privacy. However, multimodal large language models (MLLMs) that process images and video simultaneously have remained stubbornly difficult to shrink. The computational overhead required to understand visual tokens usually exceeds the thermal and memory limits of a standard smartphone, leaving a gap between the promise of mobile AI and its actual utility. MiniCPM-V 4.6 arrives as a direct response to this tension, attempting to prove that high-fidelity visual understanding does not require a server farm.
The Architecture of Mobile Multimodality
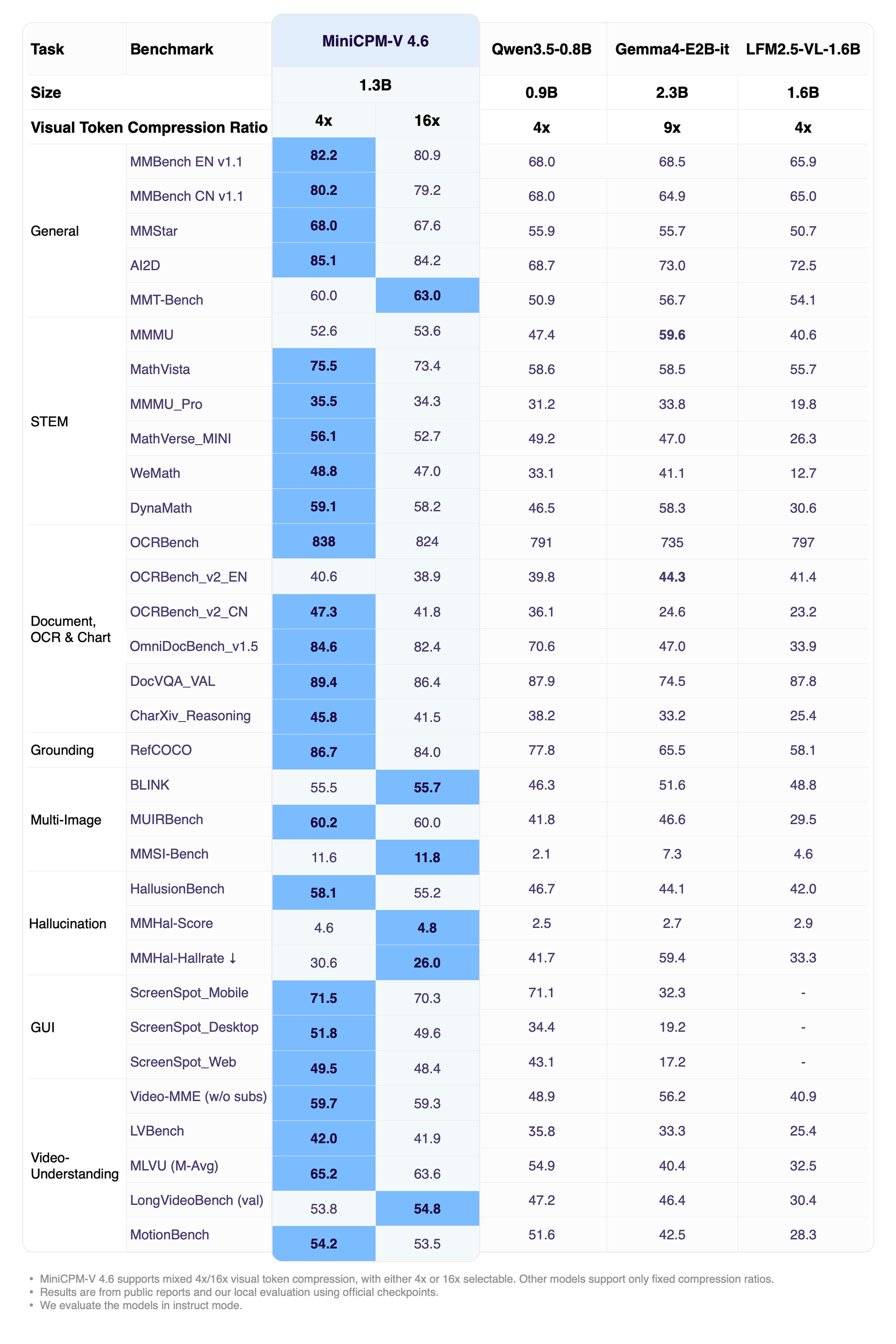
MiniCPM-V 4.6 is engineered as a hybrid system, combining the SigLIP2-400M vision encoder with the Qwen3.5-0.8B language model. The core innovation lies in its approach to visual token compression. In traditional MLLMs, images are broken down into a vast number of tokens, which quickly consume the model's context window and slow down inference. MiniCPM-V 4.6 introduces a flexible compression mechanism that supports mixed compression rates of 4x and 16x. This allows the system to balance precision and speed depending on the complexity of the visual input.
To further optimize the pipeline, the model integrates LLaVA-UHD v4 high-resolution image understanding technology. This integration specifically targets the visual encoding phase, reducing the floating-point operations (FLOPs) by more than 50 percent. By slashing the raw mathematical workload required to process an image, the model reduces the strain on mobile GPUs and NPUs. For developers looking to integrate this model into their current workflows, the installation process is streamlined through the following command:
pip install "transformers[torch]>=5.7.0" torchvision torchcodecBecause the torchcodec library used for video decoding can occasionally conflict with specific CUDA versions, an alternative installation path using the PyAV library is recommended for stability:
pip install "transformers[torch]>=5.7.0" torchvision avThe Efficiency Gap and Performance Paradox
While the technical specifications provide the foundation, the actual impact of MiniCPM-V 4.6 is found in its performance-to-size ratio. In the Artificial Analysis Intelligence Index, the model achieved a score of 13. To put this in perspective, it outperforms larger models such as Qwen3.5-0.8B, which scored 10, and Ministral 3 3B, which scored 11. The most striking disparity appears when comparing it to the Qwen3.5-0.8B-Thinking model. MiniCPM-V 4.6 manages to deliver higher intelligence scores while reducing token costs by 43x. This is not merely a marginal improvement but a fundamental shift in the cost of intelligence for mobile applications.
This efficiency extends to throughput as well, with the model processing tokens approximately 1.5x faster than Qwen3.5-0.8B. When tested across a battery of industry benchmarks including OpenCompass, RefCOCO, HallusionBench, MUIRBench, and OCRBench, MiniCPM-V 4.6 demonstrated capabilities on par with the Qwen3.5 2B model. This means a significantly smaller model is achieving the visual-linguistic understanding of a model twice its size.
This performance profile makes the model viable for deployment across all major mobile ecosystems, including iOS, Android, and HarmonyOS. To facilitate this, the model is compatible with a wide array of inference frameworks such as vLLM, SGLang, llama.cpp, and Ollama. For those needing to adapt the model to specific industry verticals, fine-tuning is supported through SWIFT and LLaMA-Factory. Furthermore, to ensure the model can run on consumer-grade hardware with limited RAM, it supports multiple quantization formats including GGUF, BNB, AWQ, and GPTQ. These formats allow the model to maintain high accuracy while drastically reducing its memory footprint, enabling real-time image and video analysis directly on a handheld device.
MiniCPM-V 4.6 transforms the mobile device from a mere interface for cloud AI into a standalone engine for multimodal intelligence.



