1.5배. MiniCPM-V 4.6(초경량 멀티모달 모델)가 Qwen3.5-0.8B(언어 처리 모델) 대비 보여주는 토큰 처리 속도의 향상 수치다. 데이터가 지나가는 통로를 넓혀 정체 없이 정보를 쏟아내는 고속도로를 뚫은 것과 같다. 그리고 이번 주 깃허브 트렌드에서 이 모델이 주목받으며 온디바이스 AI(기기 자체에서 구동되는 인공지능)의 새로운 기준점이 제시되었다.
시각 토큰 압축과 모바일 최적화 설계
연구팀은 SigLIP2-400M(시각 정보 처리 인코더)과 Qwen3.5-0.8B(언어 처리 모델)를 결합해 모델을 설계했다. 시각적 토큰을 4배에서 16배까지 혼합 압축하여 처리 속도와 정확도의 균형을 유연하게 조절하도록 만든 것이 핵심이다. LLaVA-UHD v4(고해상도 이미지 이해 기술)를 적용해 시각 인코딩 과정에서 발생하는 부동소수점 연산량(컴퓨터가 계산하는 양)을 50퍼센트 이상 절감했다. 개발자가 즉시 환경을 구축하기 위한 설치 명령어는 다음과 같다.
pip install "transformers[torch]>=5.7.0" torchvision torchcodec비디오 디코딩에 사용되는 torchcodec(비디오 처리 라이브러리)가 특정 CUDA(엔비디아 GPU 가속 라이브러리) 버전과 충돌하는 사례가 보고된다. 이 경우 PyAV(비디오 처리 라이브러리)를 사용하는 아래의 대안 경로가 권장된다.
pip install "transformers[torch]>=5.7.0" torchvision av체급을 뛰어넘는 벤치마크와 배포 확장성
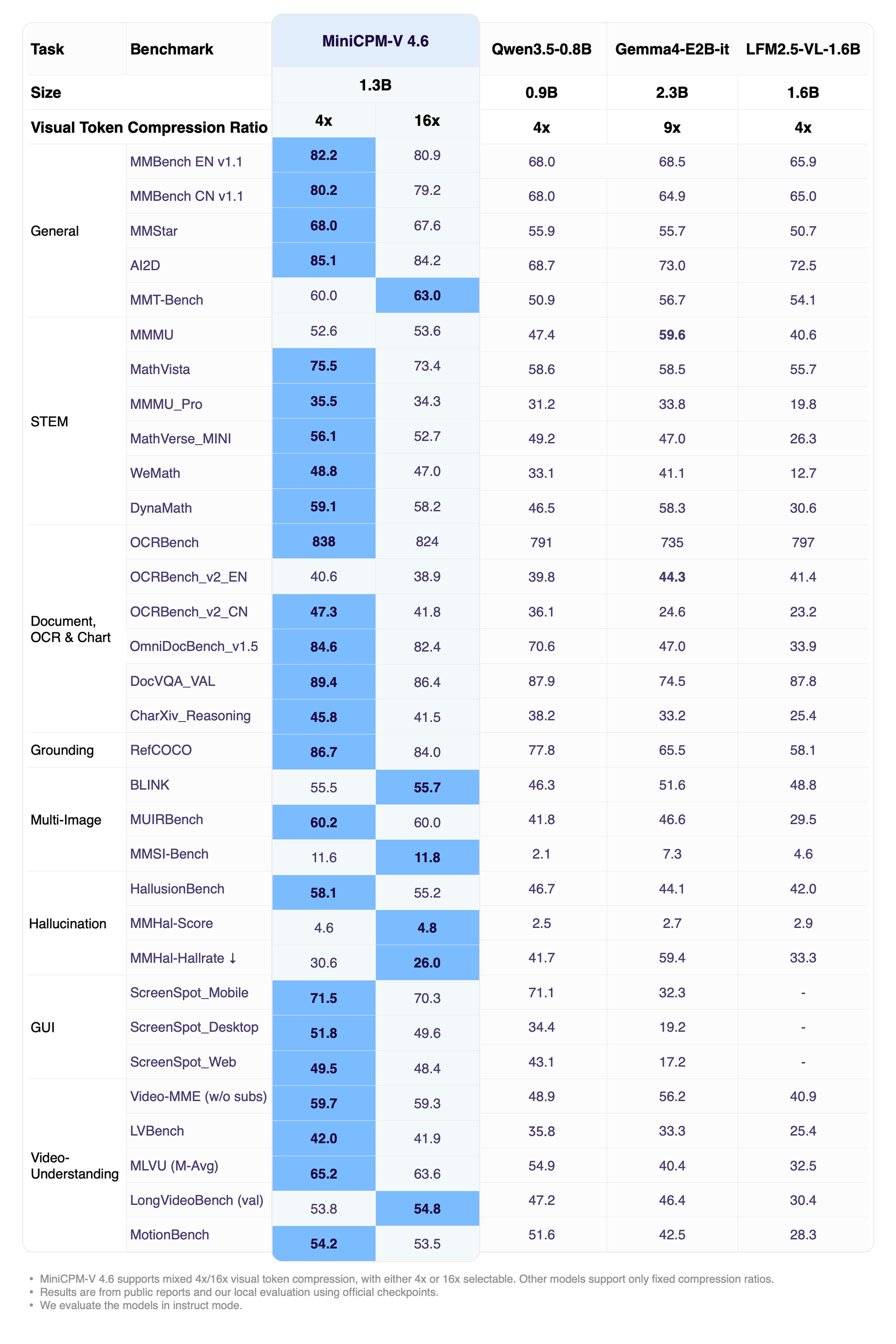
기존 거대 모델들이 점유하던 성능 지표의 기준이 바뀌고 있다. Artificial Analysis Intelligence Index(AI 성능 측정 지표)에서 MiniCPM-V 4.6는 13점을 기록하며 Qwen3.5-0.8B의 10점과 Ministral 3 3B(경량 언어 모델)의 11점을 모두 앞질렀다. 특히 Qwen3.5-0.8B-Thinking 모델과 비교하면 토큰 비용을 43배나 줄이면서도 더 높은 성능 점수를 기록했다. OpenCompass, RefCOCO, HallusionBench, MUIRBench, OCRBench 등 여러 벤치마크에서도 Qwen3.5 2B 수준의 능력을 입증하며 시각 언어 이해 능력을 보여주었다.
개발자가 체감하는 가장 큰 변화는 배포 환경의 제약이 사라졌다는 점이다. iOS, 안드로이드, HarmonyOS(화웨이 운영체제) 등 주요 모바일 플랫폼 모두에 배포가 가능하다. vLLM(고성능 추론 엔진), SGLang(구조화된 생성 언어), llama.cpp(C++ 기반 추론 도구), Ollama(로컬 모델 실행 도구) 같은 추론 프레임워크를 통해 모델을 즉시 구동할 수 있다.
특정 도메인에 맞게 모델을 최적화하려는 시도도 가능하다. SWIFT(효율적 미세 조정 프레임워크)나 LLaMA-Factory(모델 학습 도구)를 이용해 미세 조정(특정 목적에 맞게 모델을 추가 학습시키는 과정)을 진행할 수 있는 경로가 마련되었다. 또한 메모리 사용량을 극단적으로 줄이기 위해 GGUF, BNB, AWQ, GPTQ(모델의 정밀도를 낮춰 용량을 줄이는 양자화 방식)와 같은 다양한 양자화 형식을 지원한다. 이를 통해 소비자용 GPU나 모바일 기기의 제한된 램(RAM) 환경에서도 원활한 추론이 가능하다.
이제 AI의 경쟁력은 모델의 절대적인 크기가 아니라 스마트폰이라는 좁은 공간을 얼마나 효율적으로 점유하느냐의 싸움으로 옮겨갔다.



