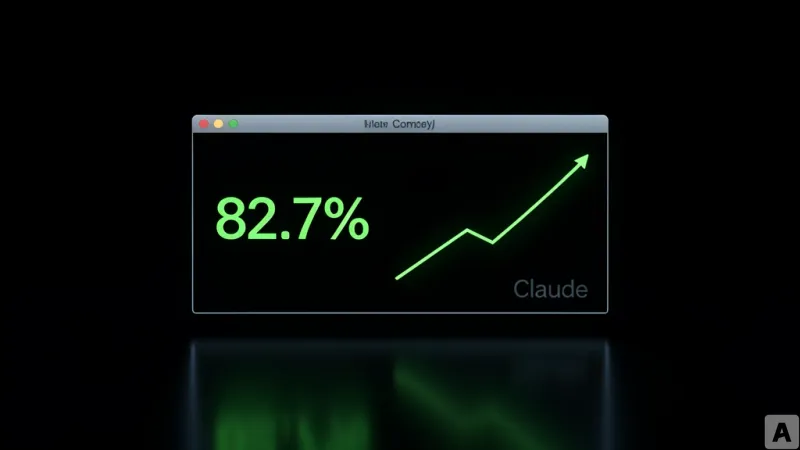
This week, the developer community has been buzzing about one thing: OpenAI's new model, GPT-5.5. The rumored codename 'Spud' is now a real product, and benchmark scores have been flying across Reddit and X (formerly Twitter) since the announcement. The standout number is 82.7% on Terminal-Bench 2.0, a test measuring a model's ability to perform tasks in a terminal environment. That score handily beats Anthropic's Opus 4.7, which held the top spot just a week ago at 69.4%. It even narrowly edges out Anthropic's limited-release high-performance model, Claude Mythos Preview, at 82.0%.
GPT-5.5 and GPT-5.5 Pro: Two Variants Released
OpenAI unveiled two variants on March 27: GPT-5.5 and GPT-5.5 Pro. The base model, GPT-5.5, is a general-purpose flagship for standard intelligence tasks. The Pro version is designed for high-stakes environments where accuracy is critical, such as legal research, data science, and advanced business analysis. The Pro model delivers more comprehensive and structured responses in complex multi-step workflows through enhanced precision, specialized logic processing, and latency optimization. Pricing starts with ChatGPT Plus ($20/month), Pro ($100–200/month), Business, and Enterprise subscribers, rolling out sequentially. The Pro model is available to Pro-tier subscribers and above. API access is not yet open; OpenAI says it will arrive "very soon." The company notes that additional safety measures are required for API deployment and is currently working with partners and customers on security requirements for large-scale serving.
From Step-by-Step Prompts to Autonomous Judgment
Older models required users to provide detailed, step-by-step instructions to avoid hallucinations when handling complex tasks. GPT-5.5 fundamentally changes this pattern. OpenAI President Greg Brockman explained, "What's special about this model is that it does more with far fewer instructions. It looks at an ambiguous problem and figures out what needs to happen next on its own." GPT-5.5 is built for agentic performance — autonomous task execution — in coding, computer use, and scientific research. It handles online research, debugging complex codebases, and tasks that span documents and spreadsheets without human intervention. On the internal benchmark 'Expert-SWE' — a long-duration coding task with a median completion time of 20 hours — GPT-5.5 achieved higher performance with fewer tokens than GPT-5.4. Notably, the 'GPT-5.5 Thinking' mode allocates more internal 'compute time' before responding, verifying assumptions to produce smarter, more concise answers.
Developers Will Notice the Latency and Efficiency Gains
Larger models typically suffer from slower response times, but GPT-5.5 maintains the same per-token latency as its predecessor, GPT-5.4, while delivering higher intelligence. OpenAI serves GPT-5.5 on NVIDIA GB200 and GB300 NVL72 systems, using custom heuristic algorithms — experience-based optimization rules — written by AI itself to manage task splitting and load balancing across GPU cores. This optimization has improved token generation speed by over 20%. However, competition is tighter in multi-domain reasoning (without tools). On 'Humanity's Last Exam,' GPT-5.5 Pro scored 43.1%, trailing Opus 4.7 (46.9%) and Mythos Preview (56.8%). In short, GPT-5.5 excels in practical tasks like terminal environments and coding, but still lags behind Anthropic in pure reasoning challenges. OpenAI Vice President of Research Amelia Glaze commented, "In coding, both benchmarks and trusted partner feedback confirm this is our most powerful model."
GPT-5.5 has reclaimed the 'most powerful public model' title for OpenAI, but the gap in reasoning performance remains a challenge to address in the next update.



