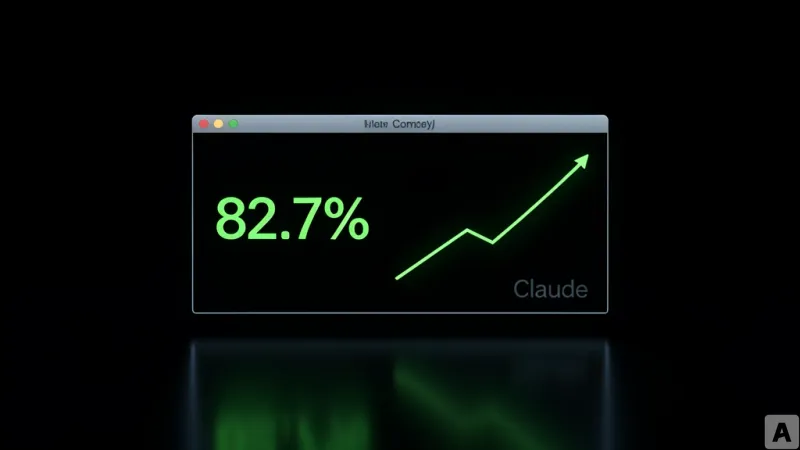
이번 주 개발자 커뮤니티가 가장 뜨겁게 달아오른 주제는 단연 OpenAI의 새 모델 GPT-5.5다. 소문으로만 돌던 코드명 'Spud(감자)'가 실제 제품으로 나왔고, 공개 직후 벤치마크 점수표가 레딧과 X(트위터)를 가로질러 공유되기 시작했다. 특히 '터미널에서 작업을 수행하는 능력'을 측정하는 Terminal-Bench 2.0에서 82.7%를 기록하며, 불과 일주일 전 선두에 올랐던 Anthropic의 Opus 4.7(69.4%)을 큰 폭으로 따돌렸다. 심지어 Anthropic이 제한적으로만 공개한 고성능 모델 Claude Mythos Preview(82.0%)조차 근소한 차이로 앞질렀다.
GPT-5.5와 GPT-5.5 Pro, 두 가지 버전으로 출시
OpenAI는 3월 27일(현지 시간) GPT-5.5와 GPT-5.5 Pro 두 가지 변종을 공개했다. 기본 모델인 GPT-5.5는 일반 지능 작업을 위한 범용 플래그십이며, Pro 버전은 법률 리서치, 데이터 과학, 고급 비즈니스 분석 등 정확성이 중요한 고난도 환경을 위해 설계됐다. Pro 모델은 향상된 정밀도와 특수 논리 처리, 지연 시간 최적화를 통해 복잡한 다단계 워크플로에서 더 포괄적이고 구조화된 응답을 제공한다. 가격은 ChatGPT Plus(월 20달러)와 Pro(월 100~200달러), Business, Enterprise 구독자부터 순차적으로 제공되며, Pro 모델은 Pro 등급 이상에서 사용할 수 있다. 단, API 접근은 아직 열리지 않았으며 OpenAI는 "매우 곧" 제공될 예정이라고 밝혔다. API 배포에는 추가 안전 장치가 필요하며, 현재 파트너 및 고객과 대규모 서빙을 위한 보안 요구사항을 협의 중이다.
예전에는 단계별 프롬프트가 필수였지만, 이제는 모델이 스스로 판단한다
기존 모델은 복잡한 작업을 처리할 때 사용자가 단계별로 세밀하게 지시해야 환각(할루시네이션)을 피할 수 있었다. GPT-5.5는 이 패턴을 근본적으로 바꿨다. OpenAI의 그렉 브록먼 사장은 "이 모델이 특별한 점은 훨씬 적은 지시로 더 많은 일을 해낸다는 것"이라며 "불명확한 문제를 보고 다음에 무슨 일이 일어나야 하는지 스스로 파악한다"고 설명했다. 실제로 GPT-5.5는 코딩, 컴퓨터 사용, 과학 연구에서 에이전트(자율 작업 수행) 성능에 초점을 맞췄다. 온라인 리서치, 복잡한 코드베이스 디버깅, 문서와 스프레드시트 사이를 오가는 작업을 사람 개입 없이 처리한다. 내부 벤치마크인 'Expert-SWE'(중간 완료 시간 20시간의 장기 코딩 과제)에서도 GPT-5.4 대비 더 적은 토큰으로 더 높은 성능을 기록했다. 특히 'GPT-5.5 Thinking' 모드는 응답 전 내부적으로 더 많은 '연산 시간'을 할애해 가정을 검증함으로써 더 똑똑하고 간결한 답변을 생성한다.
개발자가 바로 체감하는 변화는 지연 시간과 효율성이다
더 큰 모델은 보통 응답 속도가 느려지기 마련인데, GPT-5.5는 이전 모델 GPT-5.4와 동일한 토큰당 지연 시간을 유지하면서 더 높은 지능을 제공한다. OpenAI는 NVIDIA GB200 및 GB300 NVL72 시스템에서 GPT-5.5를 서빙했으며, AI가 직접 작성한 커스텀 휴리스틱 알고리즘(경험 기반 최적화 규칙)으로 GPU 코어 간 작업 분할과 부하 균형을 맞췄다. 이 최적화로 토큰 생성 속도가 20% 이상 향상됐다. 하지만 다분야 추론(도구 미사용)에서는 경쟁이 더 치열하다. 'Humanity's Last Exam'에서 GPT-5.5 Pro는 43.1%를 기록, Opus 4.7(46.9%)과 Mythos Preview(56.8%)에 뒤처졌다. 즉, GPT-5.5는 터미널 환경과 코딩 같은 실용 작업에서 강점을 보이지만, 순수 추론 과제에서는 아직 Anthropic에 밀린다. OpenAI 연구 부사장 아멜리아 글레이즈는 "코딩에서 벤치마크와 신뢰할 수 있는 파트너 피드백 모두 우리의 가장 강력한 모델"이라고 평가했다.
GPT-5.5는 OpenAI가 다시 한 번 '가장 강력한 공개 모델' 타이틀을 되찾아왔지만, 추론 영역의 격차는 다음 업데이트에서 해결해야 할 과제로 남았다.



